

-
AMD MI250 GPU 및 MosaicML로 LLM 교육IT 소식 2023. 7. 1. 22:10728x90
AMD가 NVIDIA의 독주를 막은것만으로도 의미가 있다고 생각했는데, 의외로 괜찮은 출발이네요 :)
출처 : https://www.mosaicml.com/blog/amd-mi250

PyTorch 2.0 및 ROCm 5.4의 출시와 함께 LLM 교육이 코드 변경 없이 고성능(144 TFLOP/s/GPU)으로 AMD 데이터 센터 GPU에서 즉시 작동함을 발표하게 되어 기쁩니다! 우리는 AI 하드웨어에 대한 유망한 대안을 보게 되어 매우 기쁩니다. 곧 미래의 장치와 더 큰 클러스터를 평가할 수 있기를 기대합니다.
MosaicML에서 우리는 고객을 대신하여 새로운 ML 교육 하드웨어를 찾고 있습니다. 우리는 컴퓨팅 가용성을 높이고(전 세계가 NVIDIA 공급 위기에 처해 있기 때문에!) 시장을 확장하고 교육하며 궁극적으로 모델 훈련 시간과 비용을 줄이기 위해 이렇게 합니다. 우리는 ML 교육 하드웨어의 경쟁 시장이 고객의 가격을 낮추는 데 중요하다고 생각합니다. 새 하드웨어에 대한 요구 사항은 간단합니다.
- 실제 워크로드: NVIDIA 시스템에서 훈련할 때와 동일한 수렴 및 최종 모델 품질로 16비트 정밀도(FP16 또는 BF16)에서 LLM 훈련을 지원합니다.
- 속도 및 비용: 경쟁력 있는 성능 및 달러당 성능.
- 개발자 경험: 기존 교육 스택(PyTorch, FSDP, Composer, StreamingDataset, LLM Foundry)에서 최소한의 코드 변경.
아무도 테스트를 충족하지 못했습니다. 지금까지.
PyTorch 2.0 및 ROCm 5.4+를 통해 LLM 교육은 LLM Foundry 교육 스택을 실행할 때 코드 변경 없이 AMD MI250 에서 바로 사용할 수 있습니다 .
일부 하이라이트:
- LLM 교육은 안정적이었습니다 . 매우 결정적인 LLM Foundry 교육 스택을 사용하여 AMD MI250 대 NVIDIA A100에서 MPT-1B LLM 모델을 교육하면 동일한 체크포인트에서 시작할 때 거의 동일한 손실 곡선이 생성되었습니다. 단일 교육 실행에서 AMD와 NVIDIA 간에 전환할 수도 있었습니다!
- 성능은 기존 A100 시스템과 경쟁력이 있었습니다 . MPT 모델의 훈련 처리량을 1B에서 13B 매개변수로 프로파일링한 결과 MI250의 GPU당 처리량이 A100-40GB의 80% 이내, A100-80GB의 73% 이내인 것으로 나타났습니다. AMD 소프트웨어가 개선됨에 따라 이 격차가 줄어들 것으로 예상합니다.
- 모두 작동합니다. 코드 변경이 필요하지 않았습니다.
오늘의 결과는 모두 4xMI250 GPU의 단일 노드에서 측정되었지만 더 큰 AMD GPU 클러스터를 검증하기 위해 하이퍼스케일러와 적극적으로 협력하고 있으며 곧 그 결과를 공유할 수 있기를 기대합니다! 전반적으로 우리의 초기 테스트는 AMD가 NVIDIA와 맞대결할 수 있는 효율적이고 사용하기 쉬운 소프트웨어 + 하드웨어 스택을 구축했음을 보여주었습니다.
가속기: AMD MI250 GPU
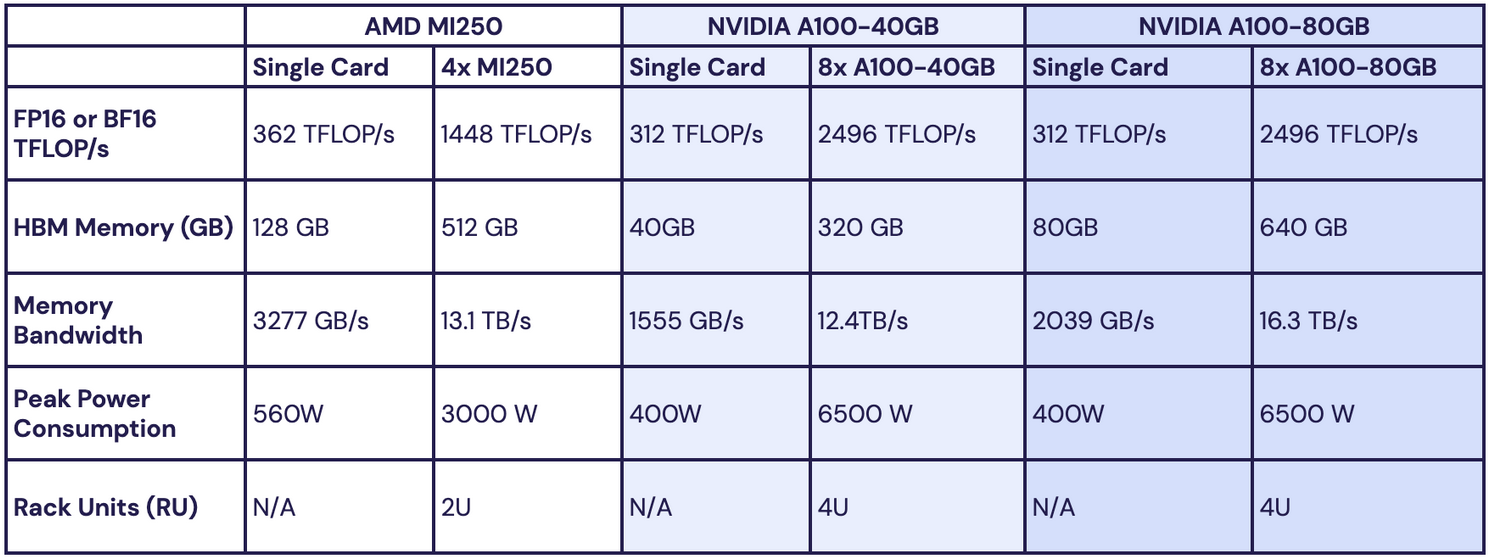
AMD MI250은 NVIDIA A100과 유사한 데이터 센터 가속기이며 HBM(High Bandwidth Memory) 및 빠른 매트릭스 곱셈을 위한 NVIDIA의 Tensor 코어와 유사한 매트릭스 코어를 갖추고 있습니다. MosaicML에서 ML 모델을 교육할 때 항상 16비트 정밀도를 사용하므로 성능 비교를 위해 16비트 형식에 중점을 둡니다. 자세한 내용은 표 1을 참조하십시오 .
MI250과 A100의 몇 가지 주목할만한 차이점은 다음과 같습니다.
- MI250은 FP16 또는 BF16의 A100보다 초당 1조 부동 소수점 연산(TFLOP/s)을 더 많이 수행할 수 있습니다.
- MI250은 가장 큰 A100(80GB)보다 더 많은 양의 HBM 메모리(128GB)를 가지고 있습니다. 이는 MI250이 교육 또는 추론을 위해 더 큰 모델을 보유할 수 있음을 의미합니다 .
- 단일 MI250의 최대 전력 소비는 단일 A100보다 높습니다. 그러나 노드의 시스템 전력 소비를 보면 GPU당 전력은 거의 같거나 AMD의 경우 조금 더 좋습니다 .
- MI250은 전통적으로 4개의 GPU가 있는 시스템 또는 "블레이드" 또는 "노드"로 제공되는 반면 A100은 전통적으로 8개의 GPU가 있는 시스템으로 제공됩니다.
전반적으로 MI250은 FLOP/s, HBM 메모리 및 메모리 대역폭에서 약간 우위에 있습니다. 그러나 MI250 GPU는 일반적으로 더 작은 시스템 구성으로 패키지되어 제공됩니다. 즉, 주어진 컴퓨팅 목표에 도달하려면 NVIDIA 시스템보다 두 배 많은 AMD 시스템을 구입해야 합니다.
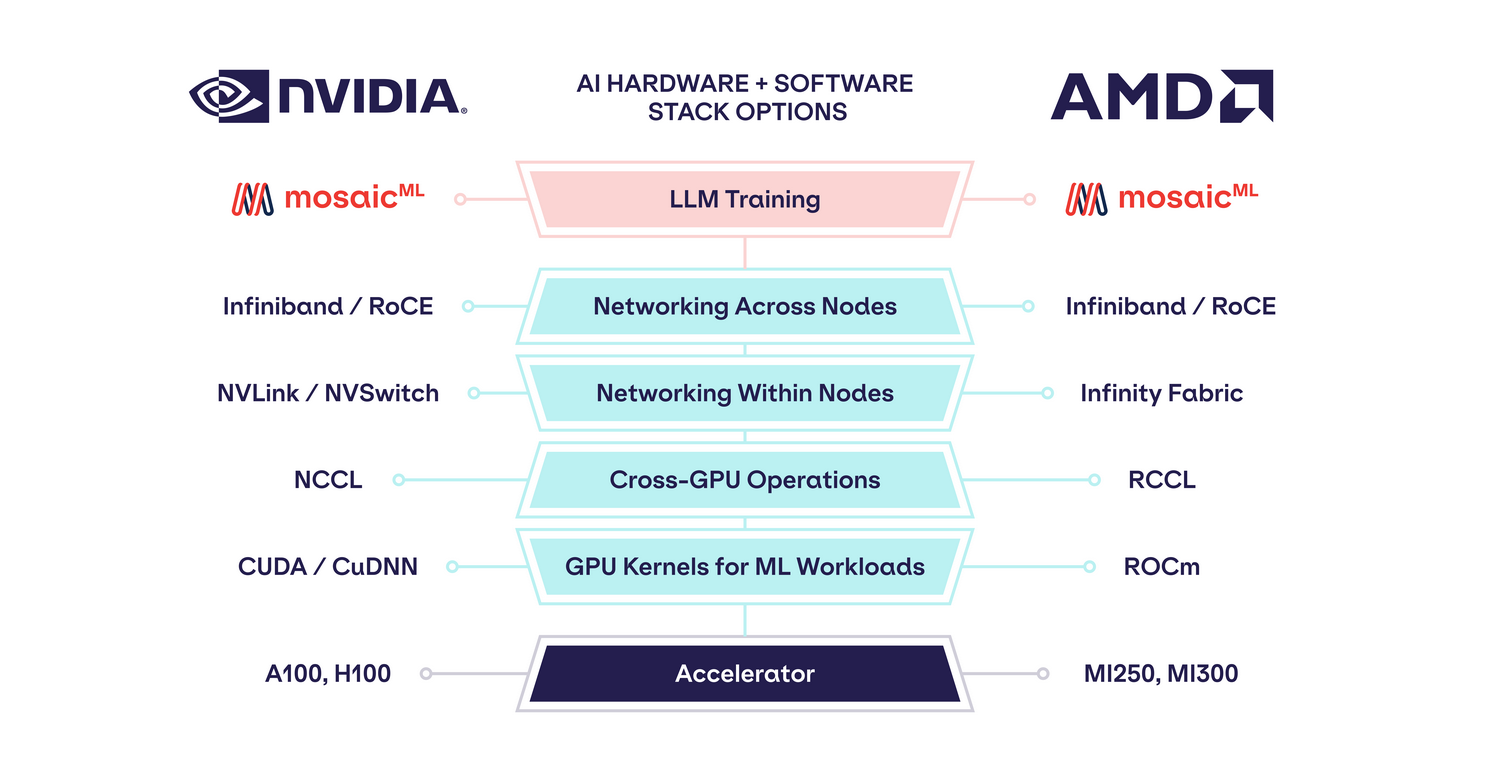
플랫폼: ROCm, RCCL, 인피니티, RoCE
좋은 소프트웨어는 대부분의 ML 교육용 칩 회사의 아킬레스건이었습니다. 고객, 데이터 과학자 및 ML 엔지니어는 PyTorch 또는 TensorFlow와 같은 프레임워크를 사용하여 높은 수준의 추상화 작업에 익숙합니다. NVIDIA GPU로 교육할 때 이러한 프레임워크는 사용자 코드를 대규모 NVIDIA 소프트웨어 컬렉션으로 변환합니다.
- CUDA/cuDNN: 행렬 곱셈, 컨볼루션, 정규화 및 ML 모델이 사용하는 기타 작업을 위한 고성능 전용 GPU 커널입니다. CUDA는 비공개 소스이며 NVIDIA GPU에서만 실행됩니다.
- NCCL: 분산 교육에 사용되는 수집, 분산, 축소와 같은 고성능 교차 GPU 작업을 위한 통신 라이브러리입니다. NCCL은 또한 NVIDIA GPU에서만 실행됩니다.
그 위에 NVIDIA 하드웨어를 분산 다중 GPU 및 다중 노드 워크로드(및 모든 심각한 ML 워크로드가 분산됨)에 매력적으로 만드는 네트워킹 인프라 계층이 있습니다.
- NVLink / NVSwitch: 노드 내 고대역폭 상호 연결.
- Infiniband 또는 RoCE(RDMA over Converged Ethernet): 노드 간 고대역폭 상호 연결. Infiniband는 대기 시간이 짧지만 RoCE보다 비용이 많이 드는 경향이 있습니다.
새로운 하드웨어 플랫폼이 상당한 성능 이점을 제공하지 않는 한 대부분의 사용자는 소프트웨어를 포팅하는 데 시간을 할애할 동기가 없습니다. 매일 새로운 모델 아키텍처와 연구 결과가 나오면서 소프트웨어가 따라잡기를 기다리는 것은 선택 사항이 아닙니다. 기존 교육 프레임워크와의 유연성 및 호환성은 새로운 하드웨어 플랫폼의 필수 요소입니다.
이러한 문제에 답하기 위해 AMD는 자체 소프트웨어 및 네트워킹 인프라 컬렉션을 개발했습니다.
- ROCm은 CUDA를 대체합니다.
- RCCL이 NCCL을 대체함
- Infinity Fabric은 노드 내에서 NVSwitch를 대체합니다.
- Infiniband 또는 RoCE 는 노드 전체에서 유사하게 지원됩니다.
스택의 각 계층에서 AMD는 소프트웨어 라이브러리(ROCm, RCCL) 또는 네트워킹 인프라(Infinity Fabric)를 구축하거나 NVIDIA의 스택과 일치하도록 기존 네트워킹 인프라(Infiniband 또는 RoCE)를 채택했습니다.
참고: 이 블로그에서는 4xMI250의 단일 노드로 제한되었으므로 아직 다중 노드 확장을 테스트하지 않았습니다. 그러나 우리는 이미 NVIDIA 시스템에서 RoCE 다중 노드 네트워킹을 사용하여 큰 성공을 거두었기 때문에(이전 블로그 참조) RoCE가 다중 노드 AMD 시스템에서도 잘 작동할 것이라고 상당히 확신합니다.
PyTorch 및 LLM Foundry와 함께 "모든 것이 잘 작동합니다"
이 모든 것이 오픈 소스 LLM Foundry 교육 스택에서 어떻게 작동합니까?
- ROCm 5.4 Docker 이미지로 시작: ` rocm/dev-ubuntu-20.04:5.4.3-complete `
- ROCm 5.4용 PyTorch 설치: `pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.4.2`
- 여기의 지침 에 따라 ROCm 기반 FlashAttention을 설치하십시오 .
- 구성 설정을 사용하여 LLM Foundry 교육 또는 미세 조정 워크로드를 실행합니다.
- 기본 `triton` 대신 `model.attn_config.attn_impl=flash`.
- 기본 `fused_crossentropy` 대신 기본 토치 CrossEntropyLoss를 사용하려면 `model.loss_fn=torch_crossentropy`.
그게 다야!
(우리는 곧 사전 구축된 AMD GPU Docker 이미지를 공유하여 설치 단계 1-3을 대체할 것입니다.)
후드 아래에서 PyTorch는 모든 부동 소수점 작업, 모든 GPU 명령 및 `torch.matmul()`, `torch.cuda.current_device()`, `inputs.to('cuda:0')와 같은 모든 분산 작업을 매핑합니다. `, `torch.dist.all_gather()` 등은 AMD 시스템에서 적절한 ROCm 및 RCCL 작업을 호출합니다 . 이것이 어떻게 생겼는지에 대한 스크린샷은 그림 1을 참조하십시오 . 동의합니다. AMD 머신에서 `torch.cuda`를 실행하는 것이 재미있지만 작동합니다!
이 접근 방식의 이점은 NVIDIA에서 AMD로 전환할 때 기존 PyTorch 코드를 변경할 필요가 없다는 것입니다. LLM Foundry 코드베이스는 순수 PyTorch를 기반으로 구축되었기 때문에 코드 변경 없이도 작동합니다. FSDP(Fully Sharded Data Parallelism)와 같은 고급 분산 교육 알고리즘도 원활하게 작동합니다. 그림 2 에서는 LLM Foundry가 있는 AMD 시스템에서 MPT 모델을 교육할 때 터미널에서 어떻게 보이는지 볼 수 있습니다. NVIDIA 시스템에서와 정확히 동일합니다.

LLM 교육 성과
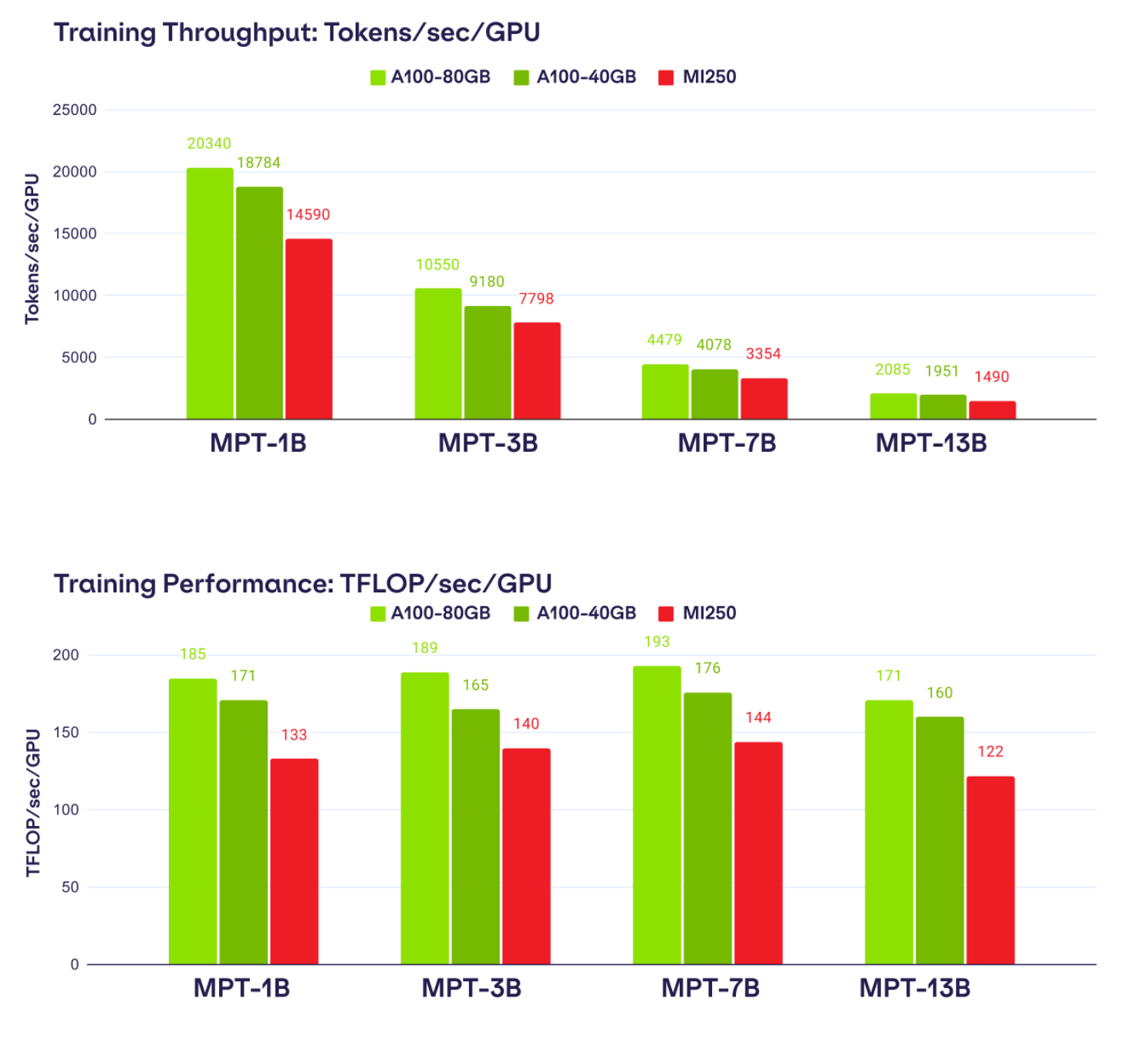
황동 압정에 대해 알아 보겠습니다. MI250은 얼마나 빠릅니까? 현재 LLM 교육 성능을 살펴보면 MI250이 A100-40GB보다 최대 80% 빠르고 A100-80GB보다 최대 73% 빠릅니다.
4xMI250-128GB, 8xA100-40GB 및 8xA100-80GB의 세 가지 시스템에서 LLM Foundry를 사용하여 1B에서 13B 매개변수까지 MPT 모델의 교육 처리량을 측정하여 이러한 수치에 도달했습니다.
각 설정에서 우리는 BF16 혼합 정밀도, FlashAttention(NVIDIA 시스템 기반의 'triton' 및 AMD 시스템 기반의 ROCm 기반) 및 sharding_strategy: FULL_SHARD를 사용하는 PyTorch FSDP를 사용하여 LLM Foundry에서 정확히 동일한 교육 스크립트를 실행했습니다. 또한 최대 성능을 달성하기 위해 각 시스템의 각 모델에 대한 마이크로배치 크기를 조정합니다.
결과는 표 2 에서 사용할 수 있는 원시 데이터와 함께 그림 3 에 표시됩니다 . 전반적으로 AMD MI250은 다양한 MPT 모델에서 A100-40GB의 GPU당 훈련 처리량의 평균 ~80% 및 A100-80GB의 ~73%를 달성하는 것으로 나타났습니다. ROCm FlashAttention 커널이 개선되거나 Triton 기반 커널로 대체됨에 따라 AMD 성능이 더 좋아질 것으로 예측합니다. 프록시 MPT 모델을 시스템 전체에서 'n_heads=1'로 비교할 때 MI250 성능을 94 이내로 가져오는 상당한 향상을 발견했습니다 . A100-40GB의 % 및 A100-80GB의 85%.
많은 MPT 모델 크기에서 볼 수 있는 일관된 성능을 감안할 때 적절한 가격으로 AMD 및 NVIDIA 시스템을 LLM 교육용으로 교체할 수 있으며 가용성 또는 비용당 성능이 더 높은 것을 사용하는 것이 좋습니다.
LLM 교육 융합
프로파일링을 넘어 일부 MPT 모델을 실제 훈련하면 어떻게 될까요? 이 블로그 작성 시점에 4xMI250의 단일 노드만 있었다는 점을 감안하여 실험을 소형 MPT-1B 모델로 제한했습니다. 한계에도 불구하고 우리가 발견한 것은 고무적이었습니다!
동일한 초기 체크포인트에서 시작하여 NVIDIA 8xA100-40GB 시스템 또는 AMD 4xMI250-128GB 시스템에서 C4 데이터 세트의 1B 토큰에 대해 MPT-1B 모델을 교육했습니다. 구체적으로 말하면, 전역 배치 크기가 512개 시퀀스이고 최대 시퀀스 길이가 2048개 토큰인 1000개 배치에 대해 교육했습니다. 그림 4 에서 우리는 손실 곡선이 1B 토큰에 대해 거의 동일하다는 것을 알 수 있습니다. 그림 5 에서 훈련의 처음 100단계를 확대 하고 손실 곡선이 실제로 겹치는 것을 확인합니다. 이러한 실행이 완전히 다른 두 개의 하드웨어 스택에서 실행된다는 점을 고려할 때 이러한 일관성을 보는 것은 작은 기적입니다!
재미를 위해 세 번째 실행을 수행하고 200배치마다 NVIDIA와 AMD GPU 간에 전환합니다. Composer의 개체 저장소 체크포인트를 사용하여 한 GPU 클러스터에서 다른 GPU 클러스터로 체크포인트를 원활하게 저장/로드합니다. 그림 4를 참조하십시오 .
이 결과는 스택의 여러 수준에서 결정론에 의해 가능합니다.
- StreamingDataset은 개체 저장소에서 데이터를 스트리밍하는 동안 탄력적인 결정성을 제공합니다. 탄력적 결정성은 노드 수, 장치 수 또는 CPU 데이터 로더 작업자 수에 관계없이 시간 단계 T에서 전역 배치의 샘플 집합이 결정적임을 의미합니다. 객체 저장소의 동일한 데이터 세트에서 4xMI250 대 8xA100-40GB를 사용하여 읽기 때문에 이는 중요합니다.
- Composer의 마이크로배치 엔진은 사용된 마이크로배치 크기에 관계없이 정확한 그래디언트 계산을 가능하게 합니다. 4xMI250-128GB 시스템에서는 마이크로배치 크기 8을 사용하지만 8xA100-40GB 시스템에서는 GPU 메모리가 적기 때문에 더 작은 마이크로배치 크기 4를 사용하기 때문에 이는 중요합니다.
- 모든 실행에 대해 공유 초기 가중치 체크포인트를 사용합니다.
- 비결정적 작업(예: Dropout)은 사용하지 않습니다.
- PyTorch FSDP 및 BF16 자동 전송은 두 시스템에서 일관됩니다.
- ROCm 기반 FlashAttention과 Triton 기반 FlashAttention은 수치적으로 가깝습니다.
- CUDA와 ROCm 커널은 수치적으로 비슷합니다.
- NCCL 및 RCCL 분산 컬렉티브는 수치적으로 가깝습니다.
전반적으로 우리는 AMD 시스템에 대한 LLM 교육이 NVIDIA 시스템에 대한 교육과 안정적이고 일관된 것으로 보고하게 되어 기쁩니다. 더 큰 AMD 클러스터에 액세스하게 되면 더 큰 규모의 컨버전스 실행을 기대합니다!

무엇 향후 계획?
이 블로그에서 우리는 교육 LLM과 같은 최신 ML 워크로드를 위한 AMD 데이터 센터 GPU를 검증하기 위한 첫 번째 단계를 밟았습니다. 우리는 또한 PyTorch에 구축된 간단한 교육 스택을 사용하면서 NVIDIA와 AMD에서 실행하는 데 코드 변경이 전혀 필요하지 않았습니다. 코드베이스가 PyTorch에도 구축되어 있다면 AMD에서도 바로 사용할 수 있습니다!
다음으로 더 큰 클러스터에서 더 큰 모델을 프로파일링하여 AMD 시스템이 계속해서 규모에 맞는 성능을 발휘하는지 확인할 계획입니다. 우리는 이를 위해 오늘날 하이퍼스케일러와 적극적으로 협력하고 있으며 가까운 장래에 결과를 공유하게 되어 기쁩니다.
또한 AMD의 새로운 MI300x GPU와 NVIDIA의 최신 H100 GPU를 비교할 수 있기를 기대합니다. H100은 클라우드 데이터 센터에 막 도착하기 시작했으며 이미 큰 가능성을 보여주고 있습니다( 여기에서 H100 프로파일링 블로그 참조 ). 그러나 MI300x는 메모리 용량(192GB vs. 80GB)과 메모리 대역폭(5.2TB/s vs. 3.2TB/s)이 훨씬 더 높은 것으로 보고되었습니다. 우리는 아직 MI300x에 대한 TFLOP/s 수치를 알지 못하지만 알게 되어 기쁩니다!
또한 향후 블로그 게시물에서 NVIDIA 및 AMD 시스템 모두에 대한 추론 벤치마크와 기타 워크로드(예: 확산 모델)를 프로파일링할 계획입니다.
전반적으로 우리는 AI 교육 하드웨어의 미래 시장에 대해 매우 낙관적입니다. 좋은 옵션이 많다는 것은 더 많은 컴퓨팅 공급, 더 많은 시장 압력, 그리고 궁극적으로 자신의 모델을 훈련시키려는 사용자의 비용을 낮추는 것을 의미합니다.
MosaicML 플랫폼에서 자신의 LLM을 교육하는 데 관심이 있다면 연락하여 시작하세요 !
#amd #MI250 #MosaicML #LLM교육
'IT 소식' 카테고리의 다른 글
AMD Ryzen 7000 CPU의 스타필드 번들 프로모션 이벤트 (0) 2023.07.04 AMD는 HYPR-RX를 제 시간에 출시하지 못했습니다. (0) 2023.07.02 AMD Ryzen 5 5600X3D는 7월 7일 3D V-Cache가 포함된 MicroCenter 전용 6코어 CPU로 229달러에 출시됩니다. (0) 2023.07.01 AMD, 올 가을 Radeon RX 7900 XTX 및 Pro W7900부터 RDNA 3 GPU에 공식적으로 ROCm 지원 제공 (0) 2023.06.30 AMD EXPO 프로필이 있는 G.Skill의 24GB DDR5-6000 모듈 출시 (0) 2023.06.30