

-
AMD, Vega/Polaris 그래픽 종료: GCN 및 RDNA GPU 아키텍처 살펴보기IT 소식 2023. 11. 14. 11:41728x90

AMD는 GCN급 Vega 및 Polaris GPU에 대한 적극적인 지원 종료를 시작했습니다 . 가장 최근의 징후는 이러한 수명이 긴 그래픽 프로세서에 대한 Vulkan Linux 드라이버 지원이 종료되었다는 것입니다. Polaris 및 Vega 기반 Radeon 카드는 버그 수정 및 보안 업데이트를 계속 받을 수 있지만 Navi용으로 출시된 최신 기능 및 콘텐츠 업데이트는 더 이상 받을 수 없습니다 .
이 은퇴 프로세스는 얼마 전 Adrenaline 23.9 드라이버 패키지와 함께 시작되었습니다. 지난 9월 AMD는 GCN과 RDNA를 위한 별도의 드라이버 브랜치를 만들었으며 RDNA에만 게임 최적화 및 GPUOpen 기술이 적용되었습니다.

RDNA 및 CDNA로 대체되기 전 거의 10년 동안 AMD를 지원했던 GCN 그래픽 아키텍처를 다시 살펴보겠습니다. GCN이 폐기된 주된 이유 중 하나는 그것이 컴퓨팅 지향적 설계에 가깝고 게임 보다는 숫자 계산에 더 적합하기 때문입니다 . 또한 아무리 많은 트랜지스터를 배치하더라도 특정 지점 이상으로 확장되지 않았습니다.
결과적으로 AMD는 처음부터 다시 시작해야 합니다. 즉, GCN의 모든 내용이 폐기된 것은 아닙니다. 일부 기능은 Navi GPU에서 계속 유지되는 반면 CDNA는 본질적으로 GCN을 강화합니다 .
더 크다고 항상 더 좋은 것은 아니다
GPU는 병렬 처리를 통해 발전합니다 . 이는 SIMD 설계 에 내재된 높은 대기 시간을 숨기는 데 도움이 됩니다 . 하드웨어 활용도가 높을수록 아키텍처가 더 효율적입니다. 이는 일반적으로 수천 개의 워프/웨이브를 비행 중에 유지함으로써 달성됩니다. 따라서 GCN(및 Bulldozer)을 통해 AMD는 긴 작업 대기열과 더 긴 실행 시간을 갖춘 컴퓨팅 괴물을 만들었습니다.

AMD의 각 GCN 컴퓨팅 유닛은 각각 16개의 SP를 포함하는 4개의 SIMD 유닛으로 나누어진 64개의 셰이더(스트림 프로세서)로 구성되었습니다. SIMD 장치는 작업 대기열의 16개 항목에 대해 단일 작업을 동시에 실행합니다(벡터 실행). 4개의 SIMD 장치는 16개의 대기열 작업 항목으로 구성된 4세트를 포함하는 별도의 파면에서도 작동할 수 있습니다.
천천히 그리고 착실히…
전반적으로 각 SIMD는 전체 웨이브(64개 항목)를 실행할 수 있지만 1~2개가 아닌 4개의 클럭 사이클 에 걸쳐 실행됩니다. 이는 각 CU가 4개의 클록 사이클에 걸쳐 4개의 웨이브를 처리할 수 있음을 의미합니다. 스케줄러는 CU의 4개 웨이브 중 하나에서 SIMD 중 하나로 하나의 명령을 내릴 수 있습니다. 이는 4사이클에 걸쳐 최대 4개의 명령어 문제를 추가합니다. 또한 GCN SIMD는 컴퓨팅 유닛당 총 40개의 웨이브를 비행 중에 최대 10개까지 유지할 수 있습니다 .

불행하게도 Team Radeon의 경우 대부분의 게임은 짧은 작업 대기열을 활용하여 SIMD/CU의 활용도가 낮았습니다 . 초기 파견 후 지침이 거의 또는 전혀 발행되지 않았기 때문입니다. 반대로, 경쟁사인 GeForce 카드는 1~2사이클의 실행 시간이 더 짧기 때문에 같은 기간 동안 더 많은 명령 문제가 발생합니다.
GCN에서 RDNA로: 웨이브의 변화
RDNA의 가장 주목할만한 변화 중 하나는 매 사이클마다 32개 항목 파면을 실행할 수 있는 더 넓은 SIMD 장치를 도입한 것입니다. 컴퓨팅 유닛당 셰이더 수는 여전히 64개이지만 32개 폭의 SIMD32 유닛에 분산되어 있습니다. 또한 각 CU는 다른 CU와 쌍을 이루어 스칼라 및 명령 캐시 등을 서로 공유합니다 .
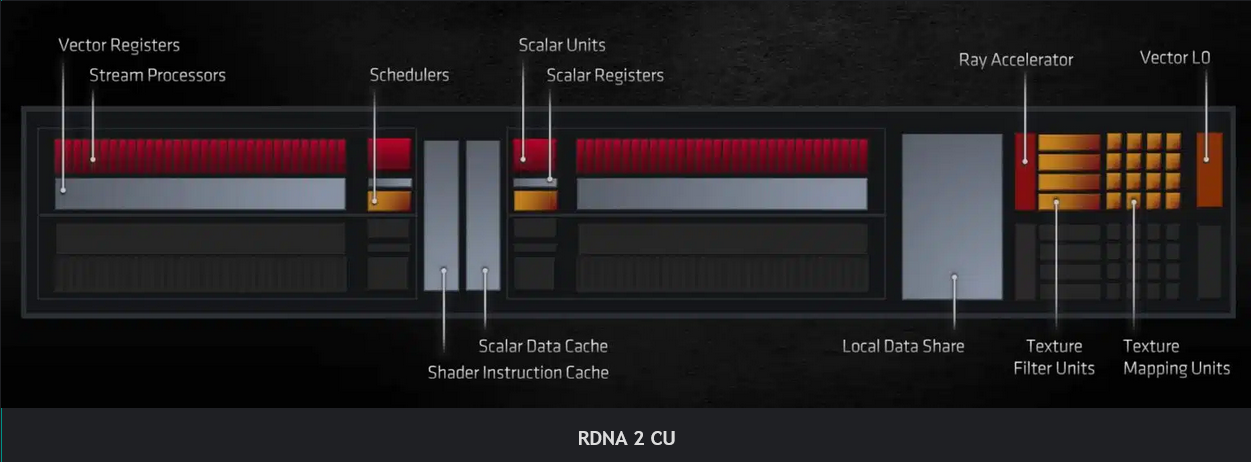
이러한 배열을 통해 하나의 클록 사이클에서 하나의 전체 파면을 실행할 수 있으므로 병목 현상이 줄어들고 IPC가 4배 향상됩니다. 웨이브프론트를 4배 더 빠르게 완료함으로써 레지스터와 캐시가 더 빠르게 확보되어 전체적으로 더 많은 명령을 스케줄링할 수 있습니다. 또한 wave32는 wave64에 비해 레지스터 수의 절반을 사용하므로 회로 복잡성과 비용이 줄어듭니다.
벡터 레지스터 파일은 더 좁은 파면에 맞게 최적화되었습니다. 각 벡터 범용 레지스터(vGPR)에는 이제 32비트 폭(FP32의 경우)인 32개의 레인이 포함되어 있으며 SIMD에는 총 1,024개의 vGPR이 포함되어 있습니다. 이는 GCN 레지스터 수의 4배 입니다 . RDNA는 또한 CU당 스칼라 단위 수를 두 배로 늘립니다 (1>2).

RDNA 1의 컴퓨팅 유닛은 사이클당 4개의 명령, 2개의 스칼라 및 2개의 벡터를 전달할 수 있습니다. 결과적으로 RDNA1 WGP는 클록당 128개의 벡터 와 4개의 스칼라의 처리량을 갖습니다 . 또한 각 SIMD는 10KB 스칼라 레지스터 덕분에 비행 중에 최대 20개의 파면을 유지할 수 있습니다.
더 많은 캐시 및 공유 캐시
GCN 그래픽 아키텍처는 두 가지 캐시 레벨에 의존했지만 RDNA는 L2와 L0 캐시 사이에 세 번째 "L1" 레이어를 추가했습니다. L0 캐시는 DCU 전용인 반면 L1 캐시는 이중 컴퓨팅 장치 그룹 전체에서 공유됩니다. 이렇게 하면 L2 캐시의 부하가 줄어듭니다. GCN에서는 코어당 L1 캐시의 모든 캐시 누락이 L2 캐시에서 처리되었습니다. RDNA에서 새로운 L1 캐시는 각 셰이더 어레이 내의 모든 캐싱 기능을 중앙 집중화합니다.

L1 그래픽 캐시는 4개의 WGP 또는 셰이더 어레이 간에 공유됩니다. L1 캐시 컨트롤러는 메모리 요청을 조정하고 클록 주기당 4개(각 L1 뱅크에 하나씩)를 전달합니다. 다른 캐시 메모리와 마찬가지로 L1 누락은 L2 캐시 에 의해 처리됩니다 .

Polaris GPU에서는 컴퓨팅 유닛만 L2 캐시의 클라이언트였습니다. RB, 복사 엔진 및 CP가 메모리에 직접 썼기 때문에 많은 L2 플러시가 발생했습니다 . Vega는 L2의 RB 클라이언트도 만들어 L2 플러시를 줄임으로써 이 디자인을 개선했습니다. RDNA는 복사 엔진도 L2의 클라이언트로 만들어 GCN 파생 상품보다 한발 앞서 나갑니다. 이렇게 하면 L2 플러시가 더욱 줄어들 것입니다.
백엔드 및 텍스처 유닛
최신 GPU의 최종 고정 기능 그래픽 단계는 RB(Render Backend) 입니다 . 깊이, 스텐실 및 알파 테스트를 수행하고 앤티앨리어싱 및 기타 최종 테스트를 위해 픽셀을 혼합합니다. 셰이더 배열의 각 RB는 클록당 4개의 출력 픽셀 속도로 픽셀을 테스트, 샘플링 및 혼합할 수 있습니다.
RDNA의 주요 변경 사항은 RB 가 그래픽 L1 캐시를 통해 데이터에 액세스하여 L2 캐시에 대한 압력을 줄이고 더 적은 수의 데이터를 이동하여 전력을 절약한다는 것입니다. GCN에서는 RB가 메모리에 직접 데이터를 썼고 , Vega에서는 L2 캐시를 통해 데이터를 썼습니다.

Navi의 Texture Unit은 Vega보다 훨씬 빠릅니다 . 로드 및 저장 처리 속도는 GCN에 비해 여러 배 빠르므로 GPU가 로드 및 저장을 통해 최대 대역폭에 더 쉽게 도달할 수 있습니다.
RDNA와 GCN: ALU 활용도 비교
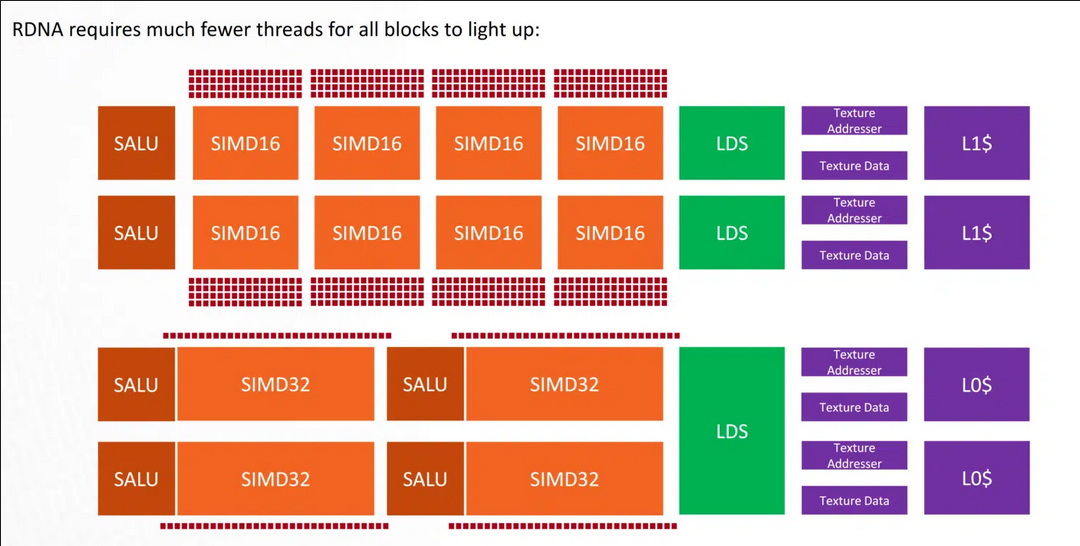
GCN에 비해 SIMD와 Navi(RDNA)의 WGP를 포화시키는 것이 훨씬 쉽습니다. 1개의 WGP(2CU)에는 100% ALU 활용도에 도달하기 위해 단 (4개의 SIMD *32개 항목) 128개의 스레드가 필요합니다. 반면 GCN은 100% 활용도에 도달하려면 512개의 스레드(2 CU * 4 SIMD * 65개 항목)가 필요했습니다.
#amd #vega #polaris #gcn #rdna #gpu
'IT 소식' 카테고리의 다른 글
AMD는 데스크탑, 노트북, 서버 부문에서 CPU 시장 점유율을 확보했습니다. (0) 2023.11.14 Gigabyte, AM5 AGESA 1.1.0.0 BIOS 펌웨어에 차세대 AMD Ryzen 데스크탑 APU 지원 추가 확인, 1월 출시 (0) 2023.11.14 AMD Ryzen 8000 시리즈는 Ryzen 9000 라인업으로 출시될 수 있습니다 (0) 2023.11.14 AMD는 차세대 칩에 Samsung 4nm 및 TSMC 3nm 노드를 활용하며 Zen 5C는 코드명 Prometheus일 수 있습니다. (0) 2023.11.14 유출된 WHQL AMD 칩셋 드라이버 업데이트는 Ryzen 8000 APU를 지원합니다 (0) 2023.11.14