

-
AMD, EPYC Bergamo 및 Genoa-X 데이터 센터 CPU, AI 지원 Instinct MI300X GPU 출시IT 소식 2023. 6. 14. 14:50728x90

AMD는 오늘 캘리포니아주 샌프란시스코에서 데이터 센터 및 AI 기술 프리미어를 개최하여 "컴퓨팅의 미래"에 대한 비전과 전략을 설명했습니다. 이 회사는 지난 11월 4세대 EPYC 9004 시리즈 서버 프로세서의 첫 번째 배치인 Genoa를 출시했으며 , 소켓당 탁월한 범용 서버 성능을 약속했습니다. 그러나 오늘 회사는 Genoa-X 및 Bergamo 로 알려진 4세대 EPYC의 다음 버전을 발표했습니다. . Genoa-X는 기술 컴퓨팅 워크로드를 강화하기 위해 3D V-Cache를 사용하는 사실상 Genoa이며, Bergamo는 보다 슬림하고 확장된 접근 방식을 사용하여 더 높은 CPU 코어 리소스가 필요한 클라우드 네이티브 컴퓨팅 워크로드를 가속화합니다. AMD는 또한 Instinct MI 300 시리즈 가속기 제품군에 대한 업데이트를 포함하여 AI 플랫폼 전략의 발전에 대해 자세히 설명했습니다.
AMD의 Bergamo, 데이터 센터용 EPYC 클라우드 네이티브 프로세서

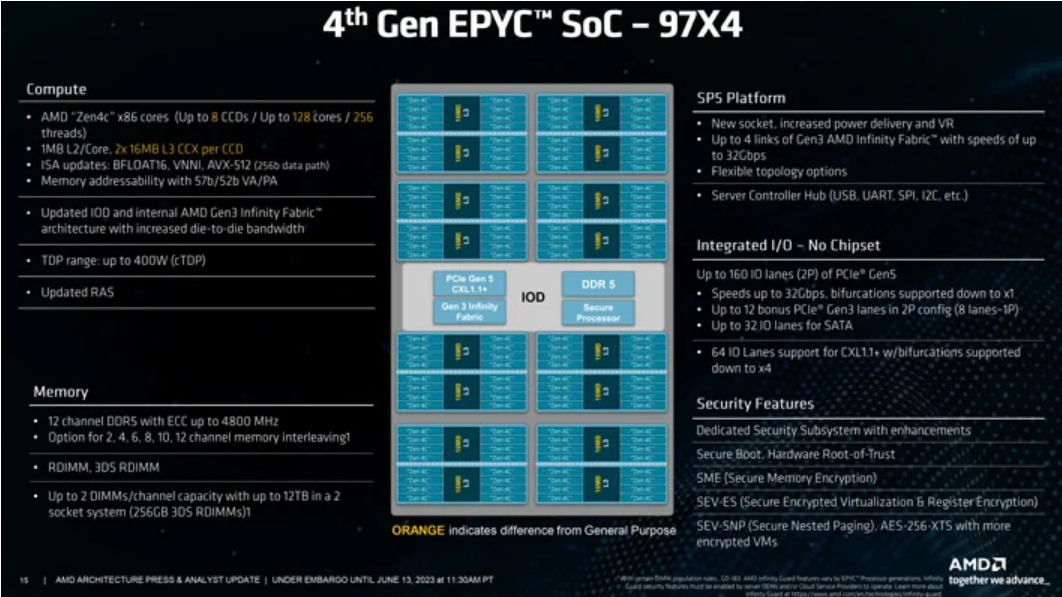
Bergamo는 소켓당 최대 128개의 코어(SMT가 있는 256개의 스레드)까지 확장할 수 있으며, 이는 동일한 설치 공간에서 Genoa보다 33% 더 많은 코어를 의미합니다. 또한 동일한 SP5 소켓을 사용하고 최고급 360W 공칭 TDP(최대 400W 구성 가능)를 유지합니다. 실제로 Bergamo는 12채널 DDR5 메모리, 128개의 PCIe Gen 5.0 레인, 최대 2P 소켓 확장성, TSMC N6에 구축된 중앙 IO 다이 및 측면 CCD를 사용하는 칩렛 레이아웃을 통해 여러 면에서 Genoa와 기능적으로 동일합니다. ) TSMC의 N5 팹 공정을 기반으로 구축되었습니다. 그러나 Bergamo에는 다른 중요한 주요 차이점이 있습니다.

새로운 EPYC Bergamo 프로세서는 처리량 효율성을 위해 Zen 4c라고 하는 Zen 4 아키텍처의 경량 변형을 사용하여 제작되었습니다. 인텔 용어 로 말하자면 Zen 4 성능 코어에 대한 효율성 코어로 생각할 수 있지만 비교는 그다지 유사하지 않습니다. AVX-512 와 같은 명령에 대한 지원을 중단하고 다른 중요한 변경 사항이 있는 Intel의 Efficiency 데스크탑 CPU 코어와 달리 AMD Zen 4c 디자인은 Zen 4의 전체 x86 ISA를 구현하지만 35% 더 적은 면적을 차지하고 더 나은 와트당 성능을 제공합니다 .
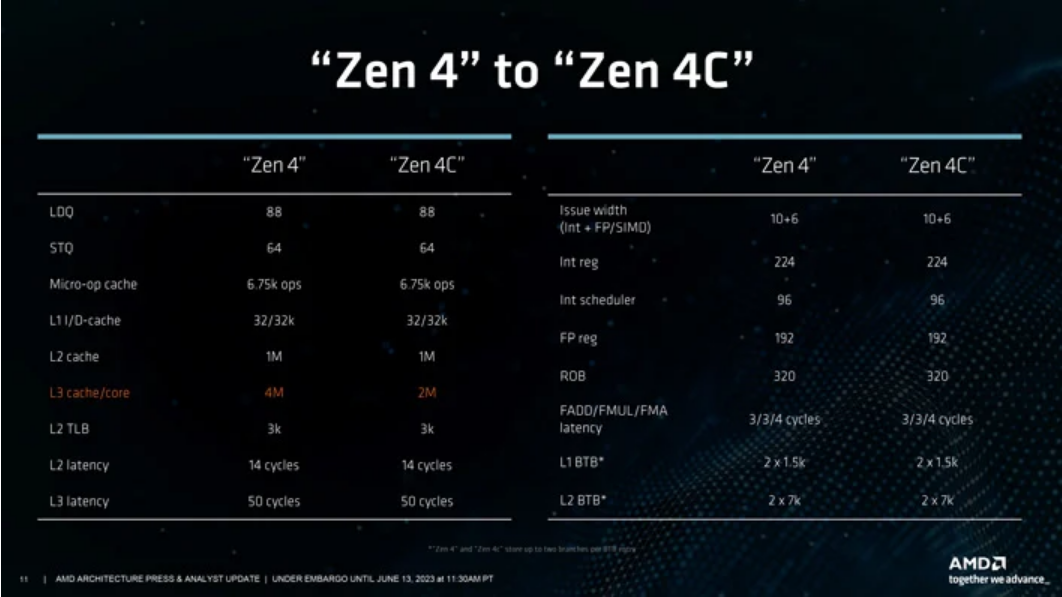
Zen 4c의 밀도 증가는 L3 캐시 감소 및 클럭 속도 완화와 같은 몇 가지 다른 양보를 통해 달성됩니다. L1 및 L2 캐시 할당은 각각 코어당 32KB 및 1MB로 동일하게 유지되지만 L3 캐시는 CCX(Core Complex)당 절반으로 줄어듭니다. CCX는 여전히 각각 최대 8개의 코어로 구성되어 있지만, 각 CCD는 줄어든 공간 덕분에 이제 2개의 CCX(16개 코어)에 맞을 수 있습니다. Genoa EPYC 9654와 비교하여 완전히 활성화된 128코어 Bergamo 칩은 L2 캐시의 128MB(Genoa의 경우 96MB)까지 확장할 수 있지만 L3는 전체적으로 256MB(Genoa의 경우 384MB)로 줄어듭니다. CCD는 다르지만 중앙 IO 다이는 Genoa와 동일합니다.
더 낮은 클럭 주파수 목표는 AMD의 설계자가 칩의 기능을 더 조밀하게 포장할 수 있도록 했습니다. 고주파 설계는 혼잡을 증가시킬 수 있는 칩 주변의 경로 레이아웃에 더 민감합니다. 따라서 Zen 4c는 Zen 4보다 세분화가 덜 필요합니다. 즉, 동일한 TSMC N5 노드 를 사용하더라도 코어 레이아웃 내에서 사용할 수 없는 데드 스페이스가 적습니다 . Bergamo의 경우 주파수가 크게 낮아지지는 않지만 수백 MHz 감소(SKU에 따라 다름)는 효율성과 전력 소비 측면에서 큰 도움이 됩니다.

이미 짐작하셨겠지만, 새로운 CCX 수학은 Bergamo가 전반적으로 더 적은 수의 CCD를 필요로 한다는 것을 의미합니다. Genoa의 경우 96코어에 도달하는 데 필요한 12개의 8코어 CCD와 비교하여 128코어에 도달하는 데 8개의 16코어 CCD만 필요합니다. 이로 인해 큰 영향을 미치지는 않지만 CCD 간의 홉 가능성이 낮기 때문에 평균적으로 코어 간 대기 시간이 줄어들 수 있습니다.

AMD는 Bergamo가 Intel의 최고 Xeon Platinum SKU 에 비해 서버당 최대 2.1배의 컨테이너 밀도 와 와트당 최대 2배의 Java 작업을 허용한다고 말합니다. 이러한 종류의 메트릭은 랙당 더 많은 인스턴스를 효율적으로 실행하면 TCO를 크게 개선하고 전체 비용을 줄일 수 있는 대규모 하이퍼스케일 배포에 매우 중요합니다.
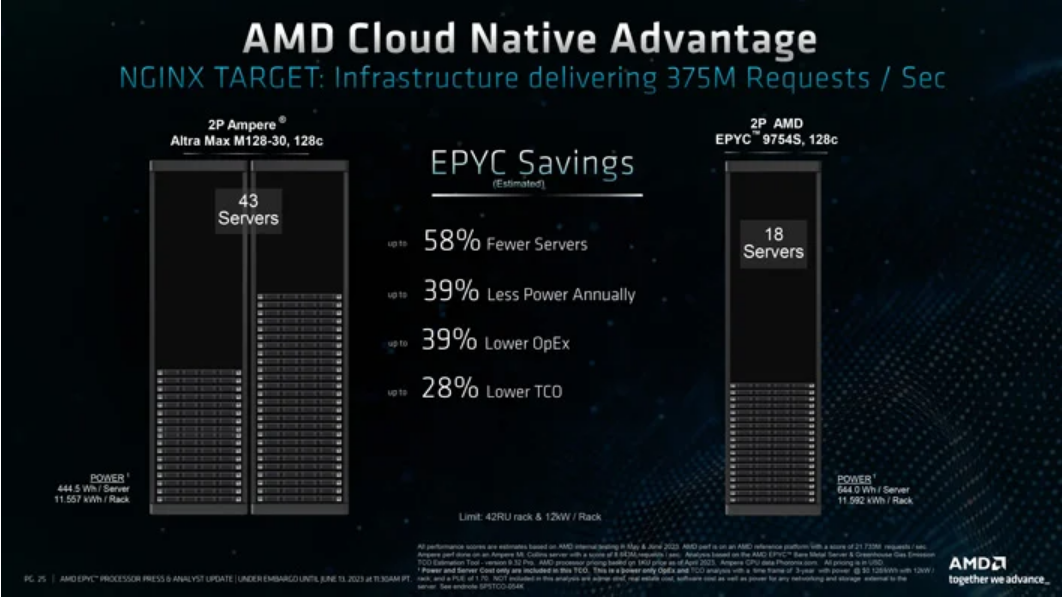
Arm 기반 Ampere 도 겨냥했습니다 . Ampere Altra Max M128-30 프로세서가 장착된 듀얼 소켓 시스템과의 비교에서 AMD는 자사의 2P EPYC 9754S 플랫폼이 초당 동일한 양의 NGINX 요청을 제공하기 위해 58% 더 적은 서버가 필요하다고 밝혔습니다. 이는 전력 소비 39% 감소, 운영 비용 39% 감소, 총소유비용(TCO) 28% 감소로 해석됩니다.

Bergamo 제품 스택은 단 3개의 SKU로 구성되며 모두 매우 높은 코어 수에 중점을 둡니다. 최고급 AMD EPYC 9754는 128개의 코어와 256개의 스레드를 갖추고 있습니다. SMT를 완전히 비활성화하는 EPYC 9754S 변형이 있습니다. 이는 보안 또는 성능 일관성 이유로 인해 핵심 독점성이 필요한 특정 고객에게 적합할 수 있습니다. 나머지 EPYC 9734는 비활성화된 CCX당 하나의 코어(총 16개)를 가지며 약간 더 낮은 전력으로 실행됩니다.
테크니컬 컴퓨팅 워크로드를 위한 3D V-Cache가 포함된 Genoa-X

제노아 보도 내용을 이미 읽었다면 제노아-X 뒤에 숨겨진 대부분의 이야기를 이미 알고 있을 것입니다. 이 칩은 최대 96개의 동일한 Zen 4 코어(Zen 4c가 아님)로 구성되지만 데스크톱용 AMD Ryzen X3D 프로세서 와 동일한 맥락에서 최대 1.1GB의 추가 L3 V-캐시가 추가로 장착됩니다. gen EPYC Milan-X CPU.

3D V-Cache는 대부분의 범용 워크로드에 실질적으로 도움이 되지 않지만 전산유체역학(CFD), 날씨 시뮬레이션, 재무 모델링 및 데이터베이스와 같이 유사하게 메모리가 제한된 기타 워크로드를 포함한 기술 컴퓨팅 워크로드를 크게 가속화할 수 있습니다.

3D V-Cache의 가치에 대한 예로 AMD는 Synopys VCS 소프트웨어에서 73% 더 빠른 RTL(Register Transfer Level) 검증을 보여주는 수치를 제시했습니다. 이것은 칩 설계에 사용되는 EDA(Electronic Design Automation) 프로그램으로, 예외적으로 컴퓨팅 집약적인 프로세스입니다.
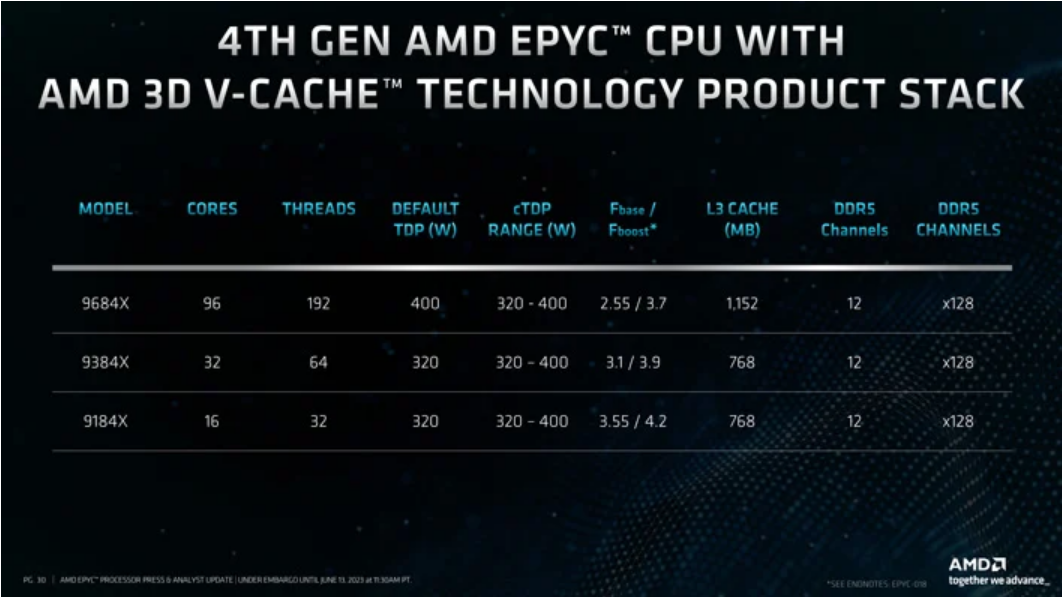
Genoa-X 플랫폼은 다음 분기부터 다양한 OEM에서 사용할 수 있습니다. 라인업은 96코어 EPYC 9684X, 32코어 EPYC 9384X 및 16코어 EPYC 9184X로 구성됩니다. 데스크톱 X3D 칩에서 볼 수 있는 것과는 반대로 이러한 SKU는 모두 Genoa 제품과 같거나 더 높은 클럭 속도를 특징으로 합니다. 예를 들어, 16코어 EPYC 9124는 최대 3.7GHz에 도달할 수 있는 반면 EPYC 9184X는 4.2GHz에 도달할 수 있습니다. 기본 TDP가 320W에서 200W로 훨씬 더 높다는 점을 감안할 때입니다.

AMD는 올해 말에 출시될 Siena의 또 다른 티저로 4세대 EPYC 프레젠테이션을 마무리했습니다. Siena는 비용 최적화된 패키지로 텔코 및 에지 사용을 위해 설계되었지만 자세한 정보는 기다려야 합니다.
AI 워크로드를 위한 AMD Instinct MI300A 및 MI300X 가속기

AI로 이동하면서 AMD는 데이터 센터, 에지 및 엔드포인트와 같은 생태계 전반에서 교육 및 추론 워크로드를 목표로 삼고 있습니다. 모든 접근 방식에는 하드웨어와 소프트웨어의 발전이 모두 필요하며 AMD도 예외는 아닙니다.

소프트웨어부터 시작하여 AMD는 지속적으로 ROCm 소프트웨어 스택을 최적화하고 있습니다 . 현재 5세대에 있는 AI 및 HPC에 최적화된 라이브러리, 컴파일러 및 도구, 런타임 세트입니다. PyTorch 및 TensorFlow와 같은 프레임워크와 함께 작동하여 AI 워크로드를 시작하기 위한 장벽을 낮추고 기존 워크로드를 쉽게 마이그레이션하며 더 높은 수준으로 가속화합니다.

생성 AI 및 LLM은 컴퓨팅 및 메모리 기능 모두에서 상당한 증가가 필요합니다. AMD는 이전에 CES에서 AI 및 HPC를 위한 최초의 데이터 센터 APU 가속기인 Instinct MI300A 가속기를 선보였습니다 . CDNA 3 GPU 아키텍처는 3개의 Zen 4 칩렛(제노아 코어 24개)과 칩의 GPU 및 CPU 측면 모두에서 액세스할 수 있는 공유 128GB 통합 HBM3 메모리를 결합합니다. Lisa Su 박사는 이전 세대 Instinct MI250X 가속기보다 8배 더 높은 성능과 5배 더 나은 효율성을 제공한다고 말합니다.

이제 AMD Instinct MI300X가 합류했습니다. 이 새로운 칩은 모든 GPU 접근 방식을 위해 3개의 Zen 4 칩렛을 2개의 CDNA 3 칩렛으로 대체합니다. 또한 메모리 용량을 5.2TB/s의 메모리 대역폭과 896GB/s의 피크 Infinity Fabric 대역폭을 갖춘 192GB의 HBM3로 확장합니다. 이는 LLM 및 AI에 대한 접근 방식을 더욱 최적화합니다.

AMD는 이것을 경쟁 상황과 관련하여 1.6배의 대역폭에서 NVIDIA의 H100 GPU보다 2.4배 더 많은 HBM 밀도를 제공한다고 말합니다. 메모리 성능은 물론 상당한 병목 현상을 완화할 수 있지만 AI 애플리케이션에서 작용하는 유일한 요소는 아닙니다. AMD는 이를 통해 동일한 결과에 더 적은 수의 GPU가 필요하므로 성능을 크게 향상시키고 TCO를 줄이는 거대한 AI 모델을 완전히 메모리 내에서 실행할 수 있다고 말합니다.

AMD는 단일 Instinct MI300X GPU 가속기에서 실행되는 HuggingFace의 Falcon-40B 모델을 시연했습니다. 샌프란시스코에 대한 시를 단 몇 초 만에 쓸 수 있었습니다. 물론 제가 할 수 있는 것보다 몇 배는 더 빨랐습니다. 이 기능은 모델을 완전히 메모리에 맞출 수 있다는 점에서 크게 인정받으며 AMD는 잠재적으로 단일 가속기에서 최대 800억 개의 매개변수까지 모델을 맞출 수 있다고 말합니다.


AMD Instinct 플랫폼은 8개의 Instinct MI300X 모듈을 결합된 1.5TB의 HBM3 메모리와 함께 그룹화합니다. 이것은 업계 표준을 사용하여 OCP(Open Compute Project) 인프라를 통해 특히 규모에 맞게 배포를 간소화합니다. Instinct 플랫폼은 특히 HuggingFace와 같은 오픈 소스 및 오픈 표준 중심 조직에서 빠른 채택을 주도할 준비가 되어 있습니다.

AMD Instinct MI300A는 현재 고객에게 샘플을 제공하고 있으며 Instinct MI300X 및 Instinct 플랫폼은 3분기에 시작될 예정입니다. AMD는 4분기에 생산량이 증가할 것으로 예상합니다.
출처 : https://quasarzone.com/bbs/qn_hardware/views/1493894
#amd #epyc
'IT 소식' 카테고리의 다른 글
AMD Zen 4c는 E-코어가 아니며 Zen 4보다 35% 작지만 IPC는 동일합니다. (0) 2023.06.15 카카오 i 클라우드, AMD 협업 확대로 클라우드 고도화 속도 낸다 (0) 2023.06.15 AMD, 클라우드 네이티브 및 기술 컴퓨팅 워크로드용 프로세서로 4세대 EPYC CPU 포트폴리오 확장 (0) 2023.06.14 Noctua, AMD AM5 프로세서용 오프셋 마운팅 출시 (0) 2023.06.14 4개의 MCD 다이가 있는 AMD Navi 32 GPU 사진 (0) 2023.06.13